The Unexpected Effectiveness of One-Shot Decompilation with Claude
Recently, I’ve been experimenting with ‘one-shot’ decompilation, leveraging Claude’s headless mode in a continuous loop.1 The results have been surprisingly positive. In the three weeks since adopting this workflow, I’ve made more progress on Snowboard Kids 2 than in the preceding three months.2

‘One-shot’ in this context means that Claude follows the prompt and exits. You hand it a function; it tries to match it, and you move on. The lack of a human-piloted feedback loop allows for significantly more throughput. I’ve left Claude for 8+ hours unattended and it will happily process functions trying to find matches. It does come with some risk, however. We’ve all seen LLMs go off the rails. Without a human present to intervene, you may return hours later to find your Claude quota exhausted, with little progress to show for it. But with the right scaffolding, the risk becomes manageable.
The purpose of this post is to document the workflow I’ve arrived at, along with a few lessons that might apply to your own projects.
The Workflow
As a user, I just run:
1. ./tools/vacuum.sh
The script (originally called ‘vacuum’ for its intended purpose of hoovering up simple functions) handles everything from there. It will churn through matchable functions until none remain, either because each has been matched or has been marked as too difficult.

Under the hood, the system has four components:
- The scorer picks the next function to attempt, prioritising those most likely to match;
- Claude performs the actual decompilation using the provided tools;
- Tools give Claude what it needs to decompile the function;
- The driver manages the lifecycle: invoking Claude, handling failures, logging progress.
The following sections cover each in detail.
The Scorer
The purpose of the scorer is to find the next easiest function for Claude to decompile. Claude is less capable than a human at this task so it would be most efficient to spend our time and energy on areas where we’re likely to make meaningful progress. This also helps lay the foundation for decompiling more complex functions, which tend to call simpler ones; understanding those dependencies makes the larger routines easier to reason about.3
Early on, I used a hand-waved formula:
score = instruction_count + 3 * branch_count + 2 * jump_count + 2 * label_count + stack_size
The idea is that a function’s complexity, and therefore decompilation difficulty, will largely be determined by its instruction count. Control flow constructs (branches and labels) are likely to increase difficulty, as are other function calls (jumps). Managing a large stack might also be tricky so it is thrown in for good measure.
This scoring approach worked reasonably well at first. Once I had logged a few hundred matched and failed functions, I switched to a logistic regression model to tune the initial weights.
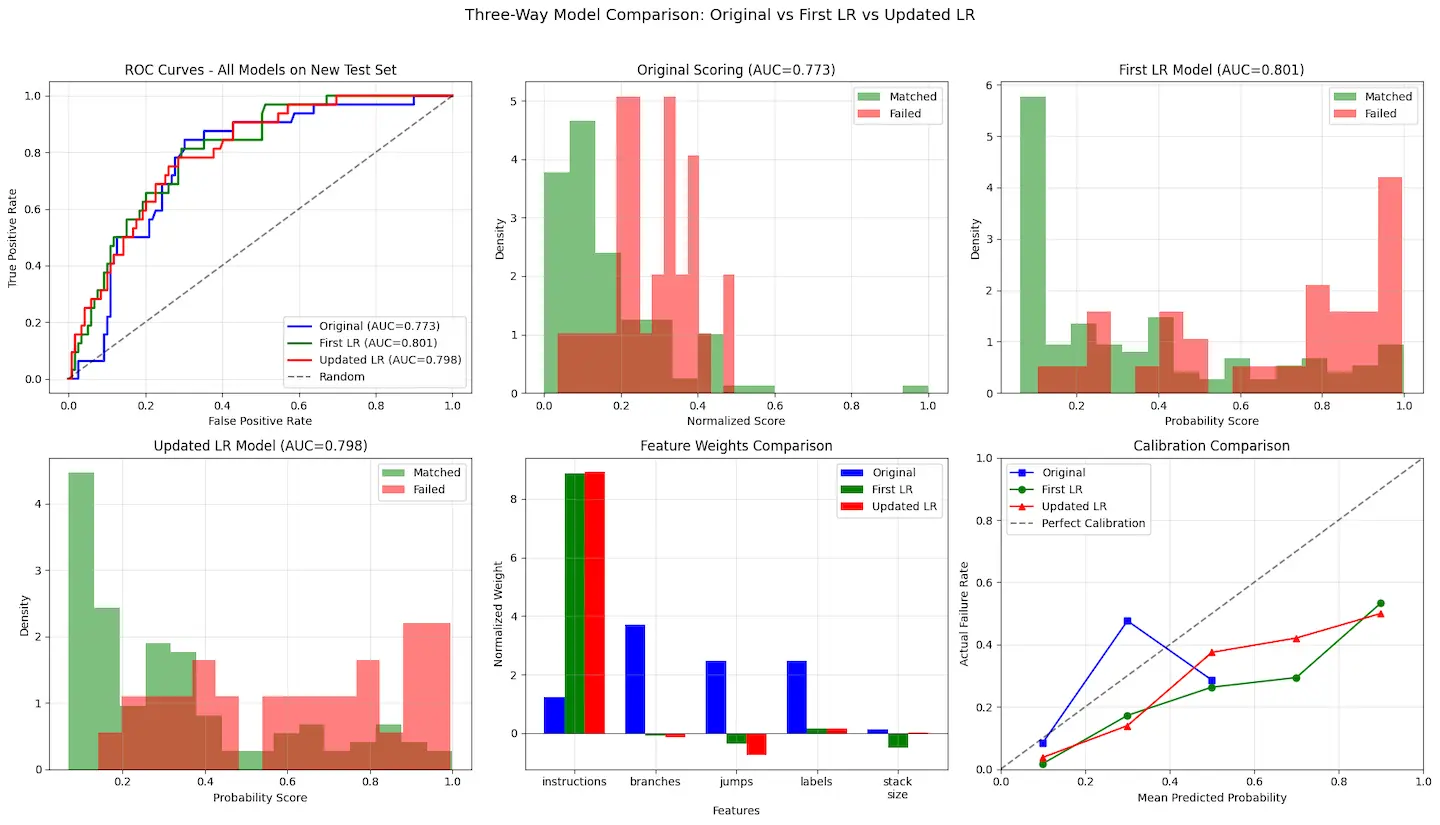
Interestingly, the model showed that stack size had almost no predictive value and appeared to contribute to overfitting. In the end I removed it. The remaining features proved more robust, but my initial guesses at the weights were way off.
I periodically retrained the model as I gathered more data, which led to marginal improvements in its accuracy.
Claude
Claude is the brains of the operation, performing the actual function decompilation. Most of these matches were performed using Opus 4.5. I do not have much data comparing Opus to Sonnet. However, in a brief experiment I conducted, Opus was able to match five out of seven functions that had been deemed too difficult by Sonnet 4.5.
The full prompt lives in the repository, but the core instructions are straightforward:
- Create a matching environment for function X.
- Follow the instructions in that environment and use the provided tools to decompile the function.
- Give up if it’s too hard. If there is no progress after more than ten attempts, the agent should move on.
- If matched: integrate into the project, verify the build, and commit. Committing is critical. This preserves progress even if Claude later ends up borking the local environment.
- If not matched: add to the difficult_functions log and exit.
The ‘give up after ten attempts’ threshold aims to prevent Claude from wasting tokens when further progress is unlikely. It was only partially successful, as Claude would still sometimes make dozens of attempts.
The Toolbox
My tooling approach has remained largely unchanged from the previous post: provide simple, Unix-like programs that Claude can compose to solve problems. I don’t add any MCP (Model Context Protocol) servers. With that said, giving Claude more autonomy has highlighted the need for defensive coding in these tools: clear error messages, graceful failures, guardrails against misuse. An ambiguous error from a tool can send Claude down a rabbit hole, wasting time and tokens.
For example, Claude is instructed to use a single script to build and verify the project: build-and-verify.sh. To mitigate Claude’s tendency to misclassify outcomes, the script provides explicit instructions on handling failures and successes:
BUILD HAS FAILED. Claude, you should treat this as a build failure. Adding new warnings or accepting a non-matching checksum count as failures.
Similarly, Claude sometimes gets lost when moving between the matching environment and the main project. We can handle this with a catchall (%:) make rule in the problematic directories which just says:
You are in a matching environment for a specific function. Only use the tools explicitly listed in this directory’s CLAUDE.md. If you’re ready to build against the main project, you need to jump back two directory levels (cd ../..)
This defensive tooling strategy has proved far more effective than prompt engineering in mitigating specific Claude failure patterns.
Another important consideration is token efficiency, which has become significantly more relevant as Claude is now run for extended periods. This is what originally motivated the decision for vacuum.sh to invoke the scorer then pass Claude the cheapest function rather than having Claude choose for itself.4 Tweaks to tooling can also help. build-and-verify.sh significantly limits build output in an effort to save tokens.
The Driver
The outer loop is a simple bash script that calls Claude repeatedly with an optional maximum iteration count. The logic is as follows:
- Call Claude with the next function to match;
- If Claude returns non-zero, back off, eventually checking at five-minute intervals in case we’ve hit a usage limit;
- Trap Ctrl-C so we can signal a stop without killing Claude mid-run and wasting the current attempt;
- Log the function name and timestamp to stdout to maintain visibility into the process;
- Append all Claude output to a file. This is invaluable for debugging failed matches; you can see exactly where Claude got stuck.
Performance vs Other Agents
I briefly tried Codex, which was getting a lot of attention when I started down this path. The results were disappointing. Codex (including the 5.1-codex-max) struggled both with effective decompilation and with following instructions in general.
The Git-related issues were the most problematic. This appears to be a known issue, although upgrading did not help in my case. Poor decompilation strategy combined with unreliable Git usage makes for a painful combination.
I haven’t yet tested Gemini or other agents.
Final Thoughts
Traditional decompilation efforts have often been multi-year, team-based projects. The primary constraint has usually been the time and availability of a handful of experts. Coding agents shift that constraint. For Snowboard Kids 2, the data so far suggests that the vast majority of functions are within reach of Claude Opus 4.5; if current trends hold, roughly 79% of functions should be matchable. Looking ahead, the limiting factor is likely to be compute and access to frontier models rather than human attention.

With that said, the tireless efforts of the decompilation community cannot be overstated. My project simply would not exist without the support of many patient people on Discord, and without tools such as Splat, m2c, decomp-permuter, asm-differ, and many others. We stand on the shoulders of giants. While the roles may change, I don’t see human experts becoming unnecessary any time soon.
The remaining functions will almost certainly be the most challenging to decompile (barring a few Claude quirks). Even when LLMs succeed, the output is often rough: pointer arithmetic instead of array access, control flow reliant on goto statements, awkward temporary variables, and other issues affecting code clarity. If the goal is to understand how these games work (or to modify them) byte-perfect but ugly matches don’t buy us much over the original assembly. It seems likely that future decompilation workflows will focus more on cleaning up and documenting LLM output than on writing code from scratch, using these matches as a base in much the same way earlier projects built on m2c output.
If you’ve made it this far, you probably have an interest in decompilation and Snowboard Kids 2. Why not help out?. Take a look at the Snowboard Kids 2 decomp GitHub page and see if you can beat the LLMs!
Something to say? You can upvote and/or join the discussion on Hacker News. You can also follow me on Bluesky for more Snowboard Kids 2 updates.
Inspired by Anand Chowdhary’s post on running Claude Code in a loop. ↩︎
Progress is currently tracked on decomp.dev. Before then, the README.md file was directly updated to reflect progress. ↩︎
This is borne out in the data although the connection is not as strong as I had originally anticipated. 62.7% of calls flow from higher complexity to lower complexity functions. ↩︎
Why didn’t I update the prompt to reflect this? Because it made Claude confused and it stopped committing changes. LLMs are weird. This needs more experimentation. ↩︎